Downloading the folktables dataset, choosing the prediction problem, a list of features, and a choice of group with respect to which to evaluate bias.
Using simple descriptive analysis to address some questions on the dataset.
Training my model on training data, incorporate a tunable model complexity and use cross-validation in order to select a good choice for the model complexity.
Auditing my model: perform an audit in which I address some questions based on the test data.
Conclusion Discussion
(Optional) Checking for Intersectional Bias in my model.
Part 1: Preparation
Download folktables
from folktables import ACSDataSource, ACSEmployment, BasicProblem, adult_filterimport numpy as npSTATE ="AL"data_source = ACSDataSource(survey_year='2018', horizon='1-Year', survey='person')acs_data = data_source.get_data(states=[STATE], download=True)acs_data.head()
RT
SERIALNO
DIVISION
SPORDER
PUMA
REGION
ST
ADJINC
PWGTP
AGEP
...
PWGTP71
PWGTP72
PWGTP73
PWGTP74
PWGTP75
PWGTP76
PWGTP77
PWGTP78
PWGTP79
PWGTP80
0
P
2018GQ0000049
6
1
1600
3
1
1013097
75
19
...
140
74
73
7
76
75
80
74
7
72
1
P
2018GQ0000058
6
1
1900
3
1
1013097
75
18
...
76
78
7
76
80
78
7
147
150
75
2
P
2018GQ0000219
6
1
2000
3
1
1013097
118
53
...
117
121
123
205
208
218
120
19
123
18
3
P
2018GQ0000246
6
1
2400
3
1
1013097
43
28
...
43
76
79
77
80
44
46
82
81
8
4
P
2018GQ0000251
6
1
2701
3
1
1013097
16
25
...
4
2
29
17
15
28
17
30
15
1
5 rows × 286 columns
Select possible features
possible_features=['AGEP', 'SCHL', 'MAR', 'RELP', 'DIS', 'ESP', 'CIT', 'MIG', 'MIL', 'ANC', 'NATIVITY', 'DEAR', 'DEYE', 'DREM', 'SEX', 'RAC1P', 'ESR']#acs_data[possible_features].head()features_to_use = [f for f in possible_features if f notin ["ESR", "RAC1P"]]
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
sum_individ =df.shape[0]print("There are", sum_individ, "individuals in the data.")
There are 38221 individuals in the data.
2. Of these individuals, what proportion have target label equal to 1? In employment prediction, these would correspond to employed individuals
num_label_1 = np.sum(df["label"] ==1)print(num_label_1/sum_individ,"of individuals have target label equal to 1 (who are employeed).")
0.4091468041129222 of individuals have target label equal to 1 (who are employeed).
3. Of these individuals, how many are in each of the groups?
print("Number of individuals that are White: ", np.sum(df["group"]==1))print("Number of individuals that are Black or African American: ", np.sum(df["group"]==2))print("Number of individuals that are other self-identified racial groups: ", np.sum(df["group"]>2))
Number of individuals that are White: 28441
Number of individuals that are Black or African American: 8070
Number of individuals that are other self-identified racial groups: 1710
4. In each group, what proportion of individuals have target label equal to 1?
The table above shows the number of employeed and unemployeed individuals in each group.
I write a for-loop to print out the proportion of employeed individual in each group:
for i inrange(1,10): prop_group_i = group_label_df[i][True]/group_label_df[i].sum() percentage =round(prop_group_i*100,2)print("In group "+str(i)+', '+str(percentage)+'%'+" of individuals have target label equal to 1.")
In group 1, 42.26% of individuals have target label equal to 1.
In group 2, 36.88% of individuals have target label equal to 1.
In group 3, 43.59% of individuals have target label equal to 1.
In group 4, 100.0% of individuals have target label equal to 1.
In group 5, 20.69% of individuals have target label equal to 1.
In group 6, 50.0% of individuals have target label equal to 1.
In group 7, 27.27% of individuals have target label equal to 1.
In group 8, 36.93% of individuals have target label equal to 1.
In group 9, 28.81% of individuals have target label equal to 1.
5. Check for intersectional trends by studying the proportion of positive target labels broken out by my chosen group labels and an additional group label.
Since I choose race (RAC1P) as my group, I then choose sex (SEX) and compute the proportion of positive labels by both race and sex.
As my analysis is not targeted on every single self-identified group, I merge all self-identified groups together to make the analysis simpler:
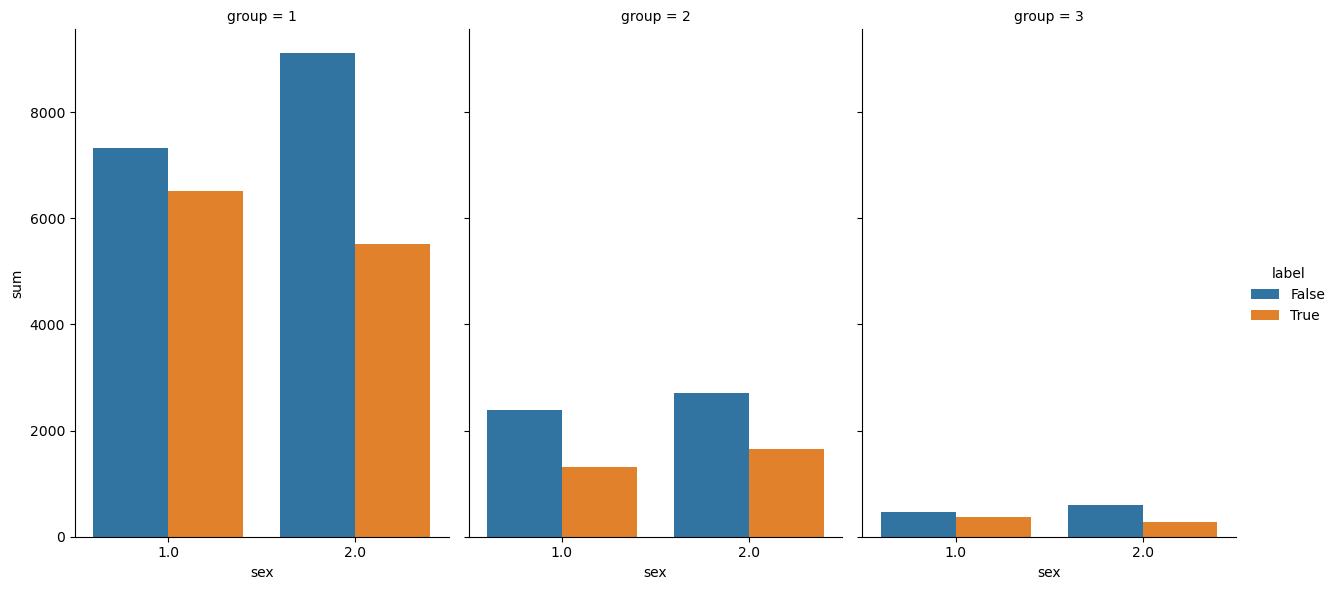
import pandas as pdimport seaborn as snsimport matplotlib as pltit_df = df.groupby(['group','SEX','label'])[[]].aggregate(len).reset_index()it_df.columns = ['group','sex','label','sum']# Aggregate all the self identified groups (i.e. group 3 and above)it_df.loc[it_df['group']>2,'group']=3it_df = it_df.groupby(['group','sex','label']).aggregate({'sum':'sum'})it_df = it_df.reset_index(names=['group','sex','label'])it_df
group
sex
label
sum
0
1
1.0
False
7317
1
1
1.0
True
6507
2
1
2.0
False
9104
3
1
2.0
True
5513
4
2
1.0
False
2381
5
2
1.0
True
1320
6
2
2.0
False
2713
7
2
2.0
True
1656
8
3
1.0
False
474
9
3
1.0
True
370
10
3
2.0
False
594
11
3
2.0
True
272
The dataframe above shows the group after merging. Now I can compute the proportion of positive label for male and female separately in each group:
Formula: number of male(or female) with positive label in group i / total number of male(or female) in group i
for i in [1,2,3]: male_pos = it_df[(it_df['group'] == i)& (it_df['sex'] ==1.0) & (it_df['label'] ==True)]['sum'].sum() male_total = it_df[(it_df['group'] == i)& (it_df['sex'] ==1.0)]['sum'].sum() female_pos = it_df[(it_df['group'] == i)& (it_df['sex'] >1.0) & (it_df['label'] ==True)]['sum'].sum() female_total = it_df[(it_df['group'] == i)& (it_df['sex'] >1.0)]['sum'].sum()print("In group "+str(i)+', '+str(round((male_pos/male_total)*100,2))+'%'+" of male have positive label.")print("In group "+str(i)+', '+str(round((female_pos/female_total)*100,2))+'%'+" of female have positive label.")
In group 1, 47.07% of male have positive label.
In group 1, 37.72% of female have positive label.
In group 2, 35.67% of male have positive label.
In group 2, 37.9% of female have positive label.
In group 3, 43.84% of male have positive label.
In group 3, 31.41% of female have positive label.
I create a barplot to compare the employment rate between male and female in each group:
import seaborn as snssns.catplot(x='sex',y ='sum', hue ='label', col ='group' ,data = it_df,kind='bar',height =6,aspect=.7)
Observations:
In group 1, the proportion of positive target label for male is greater than female.
In group 2, the proportion of positive target label for female is slightly greater than male.
In group 3 and above, the proporation of positive target label for male is greater than female.
According to the barplot and the number computed above, it can be concluded that among White people and self identified groups, the employment rate for male is greater than female. Among Black/African Americans, the employment rate for male is approximately the same between male and female.
Part 3: Train the Model
I train my DecisionTree Classifier on the training data, and selet a good choice for model complexity:
from sklearn.tree import DecisionTreeClassifier from sklearn.pipeline import make_pipelinefrom sklearn.preprocessing import StandardScalerfrom sklearn.metrics import confusion_matrixmodel = make_pipeline(StandardScaler(), DecisionTreeClassifier())model.fit(X_train, y_train)
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Tuning the max_depth in my DecisionTree Classifier:
I write a function to trace the cross validation scores under different max_depth, and find the best choice of max_depth:
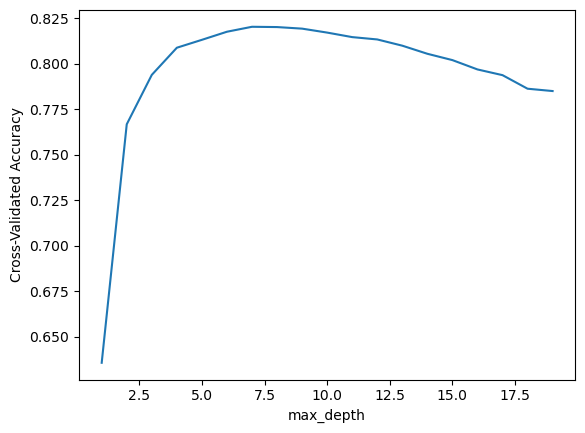
from sklearn.model_selection import cross_val_scoreacc_score = []max_depth_range = np.arange(1,20)max_score =0.0max_depth =0for n in max_depth_range: model = make_pipeline(StandardScaler(), DecisionTreeClassifier(max_depth=n)) model.fit(X_train, y_train) cv_scores = cross_val_score(model, X_train,y_train,cv=10,scoring ='accuracy') mean_score = cv_scores.mean() acc_score.append(mean_score)#keep track of the maximum cross_validation score and the corresponding depth max_score =max(max_score, mean_score)if max_score == mean_score: max_depth = nprint(f"Max_depth: {max_depth}, Max_score: {max_score}")import matplotlib.pyplot as plt%matplotlib inlinemax_depth_range = np.arange(1,20)# plot the value of C for SVM (x-axis) versus the cross-validated accuracy (y-axis)plt.plot(max_depth_range,acc_score)plt.xlabel('max_depth')plt.ylabel('Cross-Validated Accuracy')
Max_depth: 7, Max_score: 0.8202822282658613
Text(0, 0.5, 'Cross-Validated Accuracy')
Based on the plot, when max_depth = 7, the cross-validated score achieves the highest accuracy.
Compare the overall accuracy for predication and confusion matrix after tuning:
model = make_pipeline(StandardScaler(), DecisionTreeClassifier(max_depth=7))model.fit(X_train, y_train)y_hat = model.predict(X_test)print("Overall accuracy after tuning:", (y_hat == y_test).mean())confusion_matrix(y_test,y_hat, normalize ='true')
It seems that the model, after tuning, can predict the dataset better.
Part 4: Audit the Model
Now, I perform an audit in which I will address the following questions (all on test data):
Overall Measures
What is the overall accuracy of your model?
y_hat = model.predict(X_test)print("The overall accuracy of the model is:", (y_hat == y_test).mean())
The overall accuracy of the model is: 0.8205316031812474
What is the positive predictive value (PPV) of your model?
I compute TN,FN,TP,FP of my model and calculate the PPV:
cm = confusion_matrix(y_test, y_hat)TN,FN,TP,FP = cm[0][0], cm[1][0], cm[1][1], cm[0][1]PPV = TP/(TP+FP)print("The Positive Preducted Value (PPV) of my model is:", PPV)
The Positive Preducted Value (PPV) of my model is: 0.7650286259541985
What are the overall false negative and false positive rates (FNR and FPR) for your model?
FNR = FN/(TP+FN)FPR = FP/(FP+TN)print("The overall false negative rate of my model is:", FNR)print("The overall false positive rate of my model is:", FPR)
The overall false negative rate of my model is: 0.18542037084074167
The overall false positive rate of my model is: 0.17529809574657412
By-Group Measures
What is the accuracy of your model on each subgroup?
print("The accuracy of my model on group 1 is:",(y_hat == y_test)[group_test ==1].mean())print("The accuracy of my model on group 2 is:",(y_hat == y_test)[group_test ==2].mean())print("The accuracy of my model on group 3 and above is:",(y_hat == y_test)[group_test >2].mean())
The accuracy of my model on group 1 is: 0.819549929676512
The accuracy of my model on group 2 is: 0.8220048899755501
The accuracy of my model on group 3 and above is: 0.830423940149626
What is the PPV of your model on each subgroup?
cm1 = confusion_matrix(y_test[group_test ==1], y_hat[group_test ==1])cm2 = confusion_matrix(y_test[group_test ==2], y_hat[group_test ==2])cm3 = confusion_matrix(y_test[group_test >2], y_hat[group_test >2])TN1,FN1,TP1,FP1 = cm1[0][0], cm1[1][0], cm1[1][1], cm1[0][1]TN2,FN2,TP2,FP2 = cm2[0][0], cm2[1][0], cm2[1][1], cm2[0][1]TN3,FN3,TP3,FP3 = cm3[0][0], cm3[1][0], cm3[1][1], cm3[0][1]print("The PPV of my model on group 1 is:", TP1/(TP1+FP1))print("The PPV of my model on group 2 is:", TP2/(TP2+FP2))print("The PPV of my model on group 3 and above is:", TP3/(TP3+FP3))
The PPV of my model on group 1 is: 0.7759051186017478
The PPV of my model on group 2 is: 0.7263922518159807
The PPV of my model on group 3 and above is: 0.7469135802469136
What are the FNR and FPR on each subgroup?
print("The FNR of group 1 is:",FN1/(TP1+FN1),"; The FPR of group 1 is:", FP1/(FP1+TN1))print("The FNR of group 2 is:",FN2/(TP2+FN2),"; The FPR of group 2 is:", FP2/(FP2+TN2))print("The FNR of group 3 and above is:",FN3/(TP3+FN3),"; The FPR of group 3 and above is:", FP3/(FP3+TN3))
The FNR of group 1 is: 0.18518518518518517 ; The FPR of group 1 is: 0.1768908598176891
The FNR of group 2 is: 0.18699186991869918 ; The FPR of group 2 is: 0.1729150726855394
The FNR of group 3 and above is: 0.18243243243243243 ; The FPR of group 3 and above is: 0.16205533596837945
Bias Measures
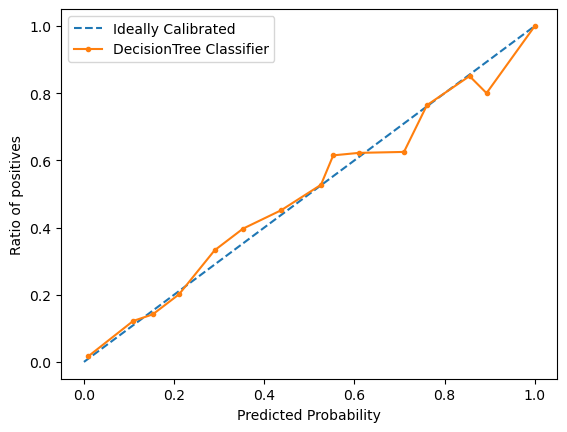
Is my model approximately calibrated?
(A model is calibrated if I binned the test samples based on their predicted probabilities, each bin’s true outcomes has a proportion close to the probabilities in the bin.)
/Users/sallyliu/opt/anaconda3/envs/ml-0451/lib/python3.9/site-packages/sklearn/calibration.py:1000: FutureWarning: The normalize argument is deprecated in v1.1 and will be removed in v1.3. Explicitly normalizing y_prob will reproduce this behavior, but it is recommended that a proper probability is used (i.e. a classifier's `predict_proba` positive class or `decision_function` output calibrated with `CalibratedClassifierCV`).
warnings.warn(
According to the calibration curve, the model is approximately calibrated.
Does my model satisfy approximate error rate balance?
(FPR and FNR are the same for all groups?)
Yes.
Based on the calculation above, FPR and FNR are approximately the same for all groups. So my model satisfies approximate error rate balance.
Does my model satisfy statistical parity?
(PPV is the same across all groups?)
No.
Based on the calculation above, group 1 has the highest PPV (0.77), while group 2 has significantly lower PPV (0.72). So my model does not satisfies statistical disparity.
Part 5: Concluding Discussion
What groups of people could stand to benefit from a system that is able to predict the label you predicted, such as income or employment status? For example, what kinds of companies might want to buy your model for commercial use?
As my model is used to predict employment status among different racial groups, I believe government and diversity orginizations might want to buy my model to keep track of the employment status and maintain the balance of employment rate among different races. Some companies might also need my model if they care about racial equality and want to promote the diversity in their firms.
Based on your bias audit, what could be the impact of deploying your model for large-scale prediction in commercial or governmental settings?
Since my model could only reach the accuracy of around 80%, there is still a 20% chance that my model may predict incorrectly. So if my model is deployed for large-scale prediction in commercial or governemnt settings, it may lead to a significant amount of misclassifications.
Based on your bias audit, do you feel that your model displays problematic bias? What kind (calibration, error rate, etc)?
Based on the analysis above, my model approximately satisfies calibration and error rate balance, but it displays problematic bias in statistical disparity.
Beyond bias, are there other potential problems associated with deploying your model that make you uncomfortable? How would you propose addressing some of these problems?
When dealing with the self identified groups, my model merge all of them together. As I noticed there are not enough data for every single self identified group (compared with the amount of data in the group 1 and group 2), I decided that it would be more efficient to combine all self-identified groups as one group. Because of that, my model can only predict all self identified groups in general, but might not be good at predicting one specific self identified group. To address this problem, I may need more data for each self identified group, so that I will be able to train my model on each group and make better prediction.
Part 6: (Optional) Intersectional Bias
Is the FNR significantly higher for Black women than it is for Black men?
Get the confusion matrix for Black Men and Black Women:
y_hat = model.predict(X_test)cm2_men = confusion_matrix(y_test[(group_test ==2)& (df['SEX'] ==1.0)], y_hat[(group_test ==2)& (df['SEX'] ==1.0)])cm2_women =confusion_matrix(y_test[(group_test ==2)& (df['SEX'] ==2.0)], y_hat[(group_test ==2)& (df['SEX'] ==2.0)])print("Confusion matrix for Black Men:")print(cm2_men)print("Confusion matrix for Black Women:")print(cm2_women)
Confusion matrix for Black Men:
[[513 83]
[ 62 261]]
Confusion matrix for Black Women:
[[568 143]
[ 76 339]]
Calculate and compare the FNR for Black Man and Black Women in my model:
FNR_black_men = cm2_men[1][0]/(cm2_men[1][0] + cm2_men[1][1])FNR_black_women = cm2_women[1][0]/(cm2_women[1][0] + cm2_women[1][1])print(f"The FNR for Black Men is {FNR_black_men}.")print(f"The FNR for Black Women is {FNR_black_women}.")
The FNR for Black Men is 0.19195046439628483.
The FNR for Black Women is 0.18313253012048192.
Conclusion:
Based on the calculation, 19% of employeed Black men are misclassified as unemployeed, while 18% of employeed Black women are misclassified as unemployeed.
The FNR is for Black Women is approximately the same as it is for Black Man, which implies that employeed Black women are as likely to be misclassified as unemployeed as employeed Black men. There does not exist a gender bias among Black/African Americans.