In this blog post, I use PyTorch to perform classification on a data set of song attributes, comparing approaches that use only lyrics, approaches that use only quantitative audio features, and approaches that use both.
Download the music dataframe, select text features and engineered features used for classification, and convert target labels (genres) into integers.
Prepare the dataloader class for my networks, create pipelines, text vectorization, and batch collation functions to return batches of data as tensor.
Implement three Neural Networks for different classifications, implement training loop and evaluation loop to train the data and compare each of the three models on validation data.
Visualize the word embeddings, and explore words that are related to emotions.
(Optional) Create some interesting visualizations that might highlight differences between genres in terms of some of the engineered features.
import pandas as pdimport torch! pip3 install torchinfofrom torchinfo import summaryfrom torch import nnimport numpy as np# for embedding visualization later! pip3 install plotlyimport plotly.express as px import plotly.io as pio# for VSCode plotly renderingpio.renderers.default ="plotly_mimetype+notebook"# for appearancepio.templates.default ="plotly_white"# for train-test splitfrom sklearn.model_selection import train_test_split# for suppressing bugged warnings from torchinfoimport warnings warnings.filterwarnings("ignore", category =UserWarning)device = torch.device("cuda"if torch.cuda.is_available() else"cpu")criterion=nn.BCEWithLogitsLoss()import osos.environ['CUDA_LAUNCH_BLOCKING'] ="1"
Requirement already satisfied: torchinfo in /Users/sallyliu/opt/anaconda3/envs/ml-0451/lib/python3.9/site-packages (1.7.2)
Requirement already satisfied: plotly in /Users/sallyliu/opt/anaconda3/envs/ml-0451/lib/python3.9/site-packages (5.14.1)
Requirement already satisfied: tenacity>=6.2.0 in /Users/sallyliu/opt/anaconda3/envs/ml-0451/lib/python3.9/site-packages (from plotly) (8.2.2)
Requirement already satisfied: packaging in /Users/sallyliu/opt/anaconda3/envs/ml-0451/lib/python3.9/site-packages (from plotly) (22.0)
%load_ext autoreload%autoreload 2
The autoreload extension is already loaded. To reload it, use:
%reload_ext autoreload
Part 1: Prepare Dataset
I download a Pandas dataframe containing information on 28,000 musical tracks produced between the years 1950 and 2019.
import pandas as pdurl ="https://raw.githubusercontent.com/PhilChodrow/PIC16B/master/datasets/tcc_ceds_music.csv"df = pd.read_csv(url)#saving original dataframedf_raw = df.copy()df.head()
Unnamed: 0
artist_name
track_name
release_date
genre
lyrics
len
dating
violence
world/life
...
sadness
feelings
danceability
loudness
acousticness
instrumentalness
valence
energy
topic
age
0
0
mukesh
mohabbat bhi jhoothi
1950
pop
hold time feel break feel untrue convince spea...
95
0.000598
0.063746
0.000598
...
0.380299
0.117175
0.357739
0.454119
0.997992
0.901822
0.339448
0.137110
sadness
1.0
1
4
frankie laine
i believe
1950
pop
believe drop rain fall grow believe darkest ni...
51
0.035537
0.096777
0.443435
...
0.001284
0.001284
0.331745
0.647540
0.954819
0.000002
0.325021
0.263240
world/life
1.0
2
6
johnnie ray
cry
1950
pop
sweetheart send letter goodbye secret feel bet...
24
0.002770
0.002770
0.002770
...
0.002770
0.225422
0.456298
0.585288
0.840361
0.000000
0.351814
0.139112
music
1.0
3
10
pérez prado
patricia
1950
pop
kiss lips want stroll charm mambo chacha merin...
54
0.048249
0.001548
0.001548
...
0.225889
0.001548
0.686992
0.744404
0.083935
0.199393
0.775350
0.743736
romantic
1.0
4
12
giorgos papadopoulos
apopse eida oneiro
1950
pop
till darling till matter know till dream live ...
48
0.001350
0.001350
0.417772
...
0.068800
0.001350
0.291671
0.646489
0.975904
0.000246
0.597073
0.394375
romantic
1.0
5 rows × 31 columns
Specify the engineered features used for classification:
Now we can see that genres have been encoded into integers.
Part 2: Prepare DataLoader
Next I want to wrap the Pandas data frame as a torch data set.
I implement my own Dataset named DataFromDF, where I implement getitem() to help separate the input data into the text features, engineered features, and labels.
from source import DataFromDFfrom torch.utils.data import Dataset, DataLoader
Perform train test split and make Datasets from each one:
Create collate_batch function that returns the batch of heeadlines as a consolidated tensor:
def collate_batch(batch): label_list, text_list, engineered_list = [], [], []for (_text, _engineered, _label) in batch:# add label to list label_list.append(label_pipeline(_label))# add text (as sequence of integers) to list processed_text = text_pipeline(_text) text_list.append(processed_text)# add engineered features to list engineered_list.append(_engineered) label_list = torch.tensor(label_list, dtype=torch.int64) engineered_list = torch.tensor(engineered_list) text_list = torch.stack(text_list)return label_list.to(device), text_list.to(device), engineered_list.to(device)
Now we can create batches of data containing both the text features and the engineered features:
I implement three Deep Neural Networks for different classifications:
from models import TextClassificationModelfrom models import EngineeredClassificationModelfrom models import CombinedNet
Training loop:
In my train() function, I pass the arguments that state whether the model being trained should use only the text features, only the engineered features, or both.
from torch.nn.modules.module import Timport timedef train(dataloader, text =True, engineered =False, k_epochs=5): loss_fn = torch.nn.CrossEntropyLoss()# Use only text featuresif (text ==True) and (engineered ==False): model = TextClassificationModel(vocab_size, embedding_dim, max_len, 3).to(device) model.double() optimizer = torch.optim.Adam(model.parameters(), lr=.1)for epoch inrange(1, k_epochs+1): epoch_start_time = time.time()# keep track of some counts for measuring accuracy total_acc, total_count =0, 0 log_interval =300 start_time = time.time() for idx, (label, text, engineered) inenumerate(dataloader):# zero gradients optimizer.zero_grad() # form prediction on batch predicted_label = model(text)# evaluate loss on prediction loss = loss_fn(predicted_label, label)# compute gradient loss.backward()# take an optimization step optimizer.step()# for printing accuracy total_acc += (predicted_label.argmax(1) == label).sum().item() total_count += label.size(0)print(f'| epoch {epoch:3d} | train accuracy {total_acc/total_count:8.3f} | time: {time.time() - epoch_start_time:5.2f}s')# Use only engineered featureselif (text ==False) and (engineered ==True): model = EngineeredClassificationModel().to(device) model.double() optimizer = torch.optim.Adam(model.parameters(), lr=.1)for epoch inrange(1, k_epochs+1): epoch_start_time = time.time()# keep track of some counts for measuring accuracy total_acc, total_count =0, 0 log_interval =300 start_time = time.time() for idx, (label, text, engineered) inenumerate(dataloader):# zero gradients optimizer.zero_grad()# form prediction on batch predicted_label = model(engineered)# evaluate loss on prediction loss = loss_fn(predicted_label, label)# compute gradient loss.backward()# take an optimization step optimizer.step()# for printing accuracy total_acc += (predicted_label.argmax(1) == label).sum().item() total_count += label.size(0)print(f'| epoch {epoch:3d} | train accuracy {total_acc/total_count:8.3f} | time: {time.time() - epoch_start_time:5.2f}s')# Use both text and engineered features elif (text==True) and (engineered ==True): model = CombinedNet(vocab_size, embedding_dim, max_len, num_class).to(device) model.double() optimizer = torch.optim.Adam(model.parameters(), lr=.1)for epoch inrange(1, k_epochs+1): epoch_start_time = time.time()# keep track of some counts for measuring accuracy total_acc, total_count =0, 0 log_interval =300 start_time = time.time() for idx, (label, text, engineered) inenumerate(dataloader):# zero gradients optimizer.zero_grad()# form prediction on batch predicted_label = model([text, engineered])# evaluate loss on prediction loss = loss_fn(predicted_label, label)# compute gradient loss.backward()# take an optimization step optimizer.step()# for printing accuracy total_acc += (predicted_label.argmax(1) == label).sum().item() total_count += label.size(0)print(f'| epoch {epoch:3d} | train accuracy {total_acc/total_count:8.3f} | time: {time.time() - epoch_start_time:5.2f}s')
Evaluation Loop:
In my evaludate() function, I use the same mechanism as the training loop to determine which part of the data should be passed to the model.
def evaluate(dataloader, text =True, engineered =False): total_acc, total_count =0, 0# Use only text featuresif (text ==True) and (engineered ==False): model = TextClassificationModel(vocab_size, embedding_dim, max_len, num_class).to(device) model.double()with torch.no_grad():for idx,(label, text, engineered) inenumerate(dataloader): predicted_label = model(text) total_acc += (predicted_label.argmax(1) == label).sum().item() total_count += label.size(0)# Use only engineered featureselif (text ==False) and (engineered ==True): model = EngineeredClassificationModel().to(device) model.double()with torch.no_grad():for idx,(label, text, engineered) inenumerate(dataloader): predicted_label = model(engineered) total_acc += (predicted_label.argmax(1) == label).sum().item() total_count += label.size(0)# Use both text and engineered featureselif (text ==True) and (engineered ==True): model = CombinedNet(vocab_size, embedding_dim, max_len, num_class).to(device) model.double()with torch.no_grad():for idx,(label, text, engineered) inenumerate(dataloader): predicted_label = model([text,engineered]) total_acc += (predicted_label.argmax(1) == label).sum().item() total_count += label.size(0)return total_acc/total_count
First Network:
Using only the lyrics to perform the classification task.
I’m interested in finding what kinds of words my model associates with the two opposite emotions – happiness and sadness, so I choose several words which I conjectured to be related to happiness and sadness and then visualize them in the scatter plot:
sad = ["sadness", "upset", "depression"]happy = ["happy", "joy", "delightful"]highlight_1 = ["laugh","smile","sun","rainbow","light","sweet","chocolate","hug","sing","dance"]highlight_2 = ["rain","cry","heartbroken","melancholy","cloudy","dark","dim","storm"]def emotion_mapper(x):if x in sad:return1elif x in happy:return4elif x in highlight_1:return3elif x in highlight_2:return2else:return0embedding_df["highlight"] = embedding_df["word"].apply(emotion_mapper)embedding_df["size"] = np.array(1.0+50*(embedding_df["highlight"] >0))sub_df = embedding_df[embedding_df["highlight"] >0]
import plotly.express as px fig = px.scatter(sub_df, x ="x0", y ="x1", color ="highlight", size =list(sub_df["size"]), size_max =10, hover_name ="word", text ="word")fig.update_traces(textposition='top center')fig.show()
To my surprise, my guessings for words of sadness and happiness do not seem to be unrelated. For example, from the plot, the distance between {“cry”, “heartbroken”, “depression”} and {“sweet”, “smile”, “joy”} are very small, suggesting that they have similarities.
On the other hands, I do find the distance between words {“dance”, “light”, “delightful”, “hug”} very small, which verifies my conjecture that those words are related to happinesss.
Part 5: Optional Extras
I want to address the following two questions:
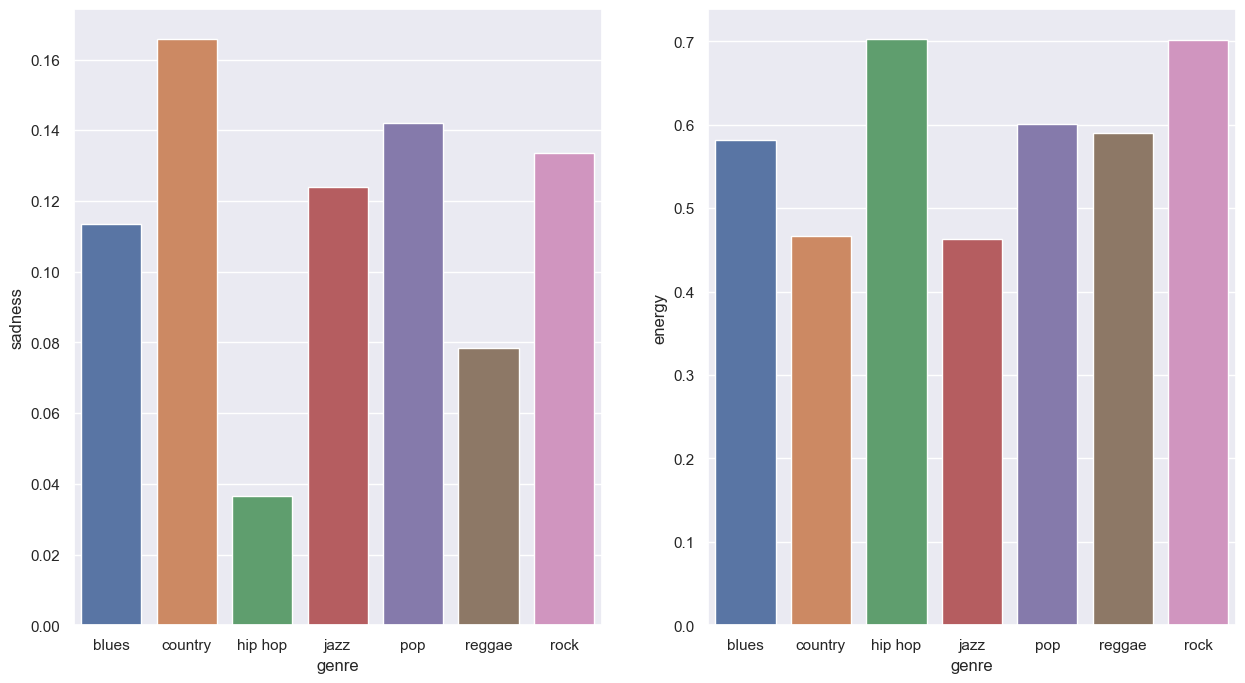
1. Does blues music tend to have more sadness than other genres? Does pop or rock have more energy?
Based on the plot above, it seems that blues does not have more sadness than other genres. In fact, country music has the most sadness among all. However, pop and rock do have more energy than other genres.
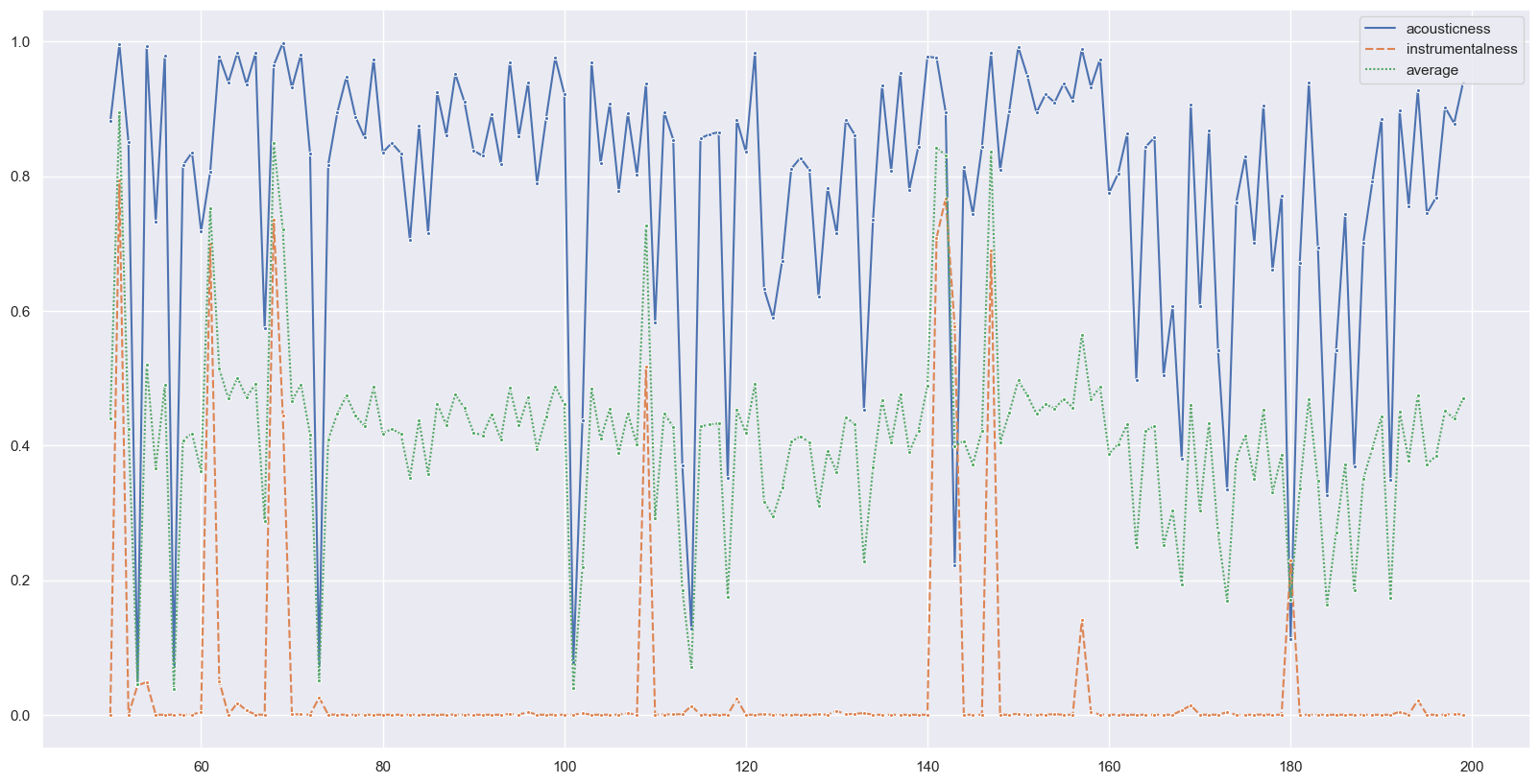
2. Are acousticness and instrumentalness similar features? Can you find any patterns in when they disagree?
Instrumentalness measures how likely the music contains no spoken word vocals
Acousticness measures how likely the music contains no “electrical amplifications of sounds”.
Theoretically, the two features are opposite: the higher the acousticness, the lower the instrumentalness, and vice versa.
/var/folders/h4/g2m40gs10fl3yvzdr50l4kb80000gn/T/ipykernel_88446/3954789753.py:1: FutureWarning:
The default value of numeric_only in DataFrame.corr is deprecated. In a future version, it will default to False. Select only valid columns or specify the value of numeric_only to silence this warning.
acousticness
instrumentalness
acousticness
1.000000
0.007762
instrumentalness
0.007762
1.000000
import matplotlib.pyplot as pltimport seaborn as snsfig, ax = plt.subplots(figsize=(20, 10))df_merge["average"] = (df_merge['acousticness']+df_merge['instrumentalness'])/2sns.lineplot(data=df_merge[50:200],ax=ax, marker=".")
According to the plot, it seems that generally, when acousticness is high, instrumentalness tends to be low.
Conclusion
Initially, I wanted to select all the seven genres to train my model for music classification. However, I found that the model became very slow (more than 20 seconds each epoch) and achieved low accuracy (appriximately 0.2), so I then decided to select only three genres for classification. The accuracy did increase, and it took less time to complete each training epoch.
However, the accuracy achieved by the model still could not be considered as high. Specifically, the model for engineered features could only achieve less than 0.4 accuracy (not much greater than random guesswork), which suggested that the model still need improvement.
Then I revised my models by adding nn.Dropout layers and increasing hidden layers. While my models still could not achieve very high accuracy, they all consistently scored above the base rate after training. So I would consider my models to be successful. Comparing all the three models, the first model (textClassification) had the best performance and could reach the accuracy of over 60%. However, the third model(combinedNet) did not show any significant improvement on training score.