The implementatino of Linear Regression in two ways (Analytical Formula and Gradient Descent).
The demonstration and testing of my implementation.
The experiments of how the increase in p_features can affect training and validation scores.
The implementation and experimentation with LASSO regularization.
The training of an instance of my LinearRegression class on the bikeshare training data.
%load_ext autoreload%autoreload 2import numpy as npimport pandas as pdimport seaborn as snsfrom matplotlib import pyplot as pltnp.seterr(all='ignore') from sklearn.datasets import make_blobs
The autoreload extension is already loaded. To reload it, use:
%reload_ext autoreload
Part 1. Implement Linear Regression
I define separate methods called fit_analytic and fit_gradient for the two methods.
from source import LinearRegressionLR = LinearRegression()
Part 2. Demo
I use the following function to create both testing and validation data, which can be used to test my implementation:
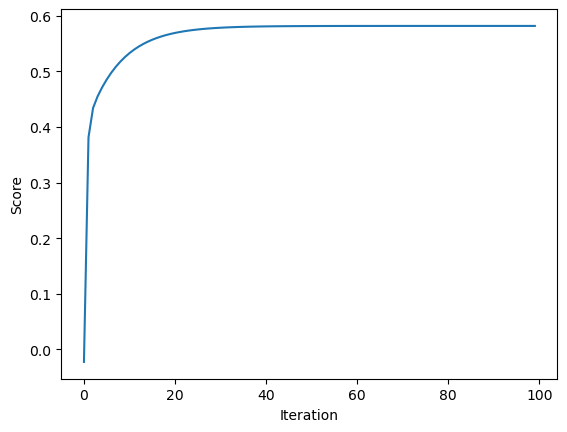
Based on the plot, the score should increase monotonically in each iteration.
Part 3. Experiments
Here, I perform an experiment in which I allow p_features, the number of features used, to increase, while holding n_train, the number of training points, constant.
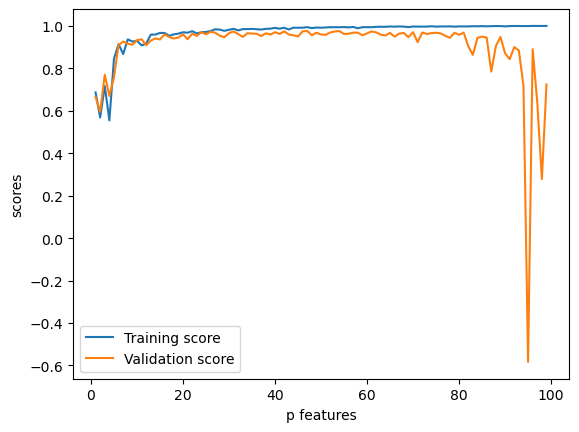
I increase p_features, from 1 all the way to n_train-1, and see the change in training score and validation score.
When n_train is larger than p_features, the linear regression model performs well on the training data, and overfitting does not occur.
When n_train is close to / not much larger than p_features, the training score increases and reaches 1.0 when p_features = n_train. However, the validation score tends to be unstable and gets arbitrarily negative in the end, meaning that the model overfitts the data.
Therefore, if we have too many features, the linear regression model may fit the training dataset very well, but it may lead to overfitting and fail to predict new data correctly.
Part 4. LASSO Regularization
I implement the LASSO Regularization from sklearn linear model:
alpha controls the strength of the regularization
from sklearn.linear_model import Lassofrom sklearn.linear_model import LassoCVL = Lasso(alpha =0.001)
Fit this model on some data and check the coefficients
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Training score: 0.9991166922705192
Validation score: 0.816469412637295
Now I replicate the same experiment I did with standard linear regression, increasing the number of features up to or even past n_train - 1, using LASSO instead of linear regression:
/Users/sallyliu/opt/anaconda3/envs/ml-0451/lib/python3.9/site-packages/sklearn/linear_model/_coordinate_descent.py:631: ConvergenceWarning: Objective did not converge. You might want to increase the number of iterations, check the scale of the features or consider increasing regularisation. Duality gap: 6.504e-02, tolerance: 5.884e-02
model = cd_fast.enet_coordinate_descent(
When n_train is not close to / larger than p_features, the linear regression model performs well on the training data, the scores are relativly stable and overfitting does not occur.
When n_train is close to / not much larger than p_features, the training score increases steadily towards 1.0. The validation score tends to be more and more unstable in the end, but it does not get arbitrarily negative. The validatio score seems to have more control. So the LASSO regulraization method may help prevent the model from overfitting.
Next, I experiment with a few values of the regularization strength alpha, and at the same time compare the validation scores for standard linear regression and lasso regularization when the number of features is large.
Set alpha = 0.01
L = Lasso(alpha =0.01)LR = LinearRegression()
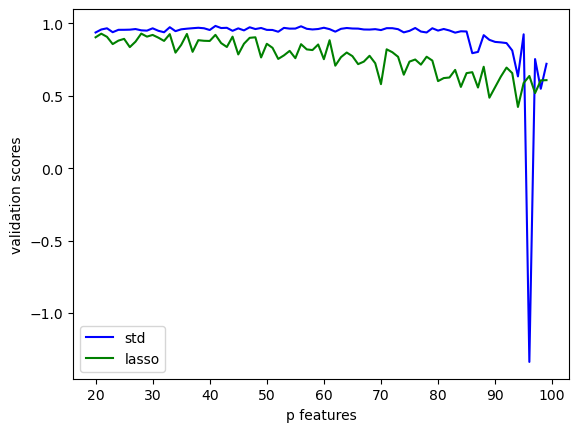
n_train =100n_val =100p_features =20noise =0.2done =Falseval_score_std = []val_score_lasso = []p_features_history = []whilenot done:# create some data X_train, y_train, X_val, y_val = LR_data(n_train, n_val, p_features, noise) LR.fit_analytic(X_train, y_train) L.fit(X_train, y_train) p_features_history.append(p_features) val_score_std.append(LR.score(X_val, y_val)) val_score_lasso.append(L.score(X_val, y_val)) p_features = p_features+1if p_features == n_train: done =Trueplt.plot(p_features_history,val_score_std, color ='blue', label ="std")plt.plot(p_features_history,val_score_lasso, color ='green',label ="lasso")plt.xlabel("p features")plt.ylabel("validation scores")legend = plt.legend() plt.show()print("Validation score for standard linear regression:", val_score_std[-5:])print("Validation score for LASSO:",val_score_lasso[-5:])
Validation score for standard linear regression: [0.9245631621914553, -1.3386640736853632, 0.7534738161505369, 0.5483048951431753, 0.7208474603034747]
Validation score for LASSO: [0.5883800034017881, 0.6368464509680394, 0.5184516531017589, 0.6061285503492282, 0.6079333676050096]
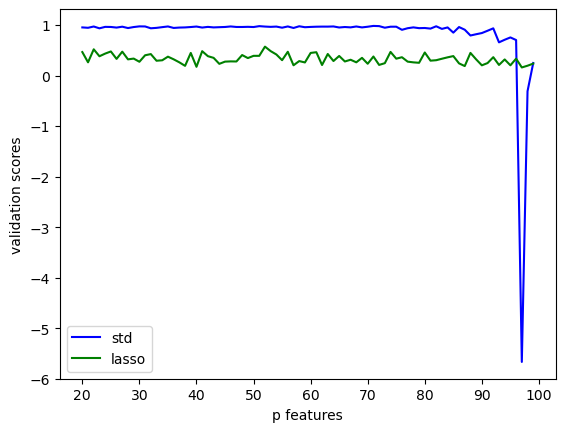
Set alpha = 0.05
L = Lasso(alpha =0.05)LR = LinearRegression()
n_train =100n_val =100p_features =20noise =0.2done =Falseval_score_std = []val_score_lasso = []p_features_history = []whilenot done:# create some data X_train, y_train, X_val, y_val = LR_data(n_train, n_val, p_features, noise) LR.fit_analytic(X_train, y_train) L.fit(X_train, y_train) p_features_history.append(p_features) val_score_std.append(LR.score(X_val, y_val)) val_score_lasso.append(L.score(X_val, y_val)) p_features = p_features+1if p_features == n_train: done =Trueplt.plot(p_features_history,val_score_std, color ='blue',label ="std")plt.plot(p_features_history,val_score_lasso, color ='green',label ="lasso")plt.xlabel("p features")plt.ylabel("validation scores")legend = plt.legend() plt.show()print("Validation score for standard linear regression:", val_score_std[-5:])print("Validation score for LASSO:",val_score_lasso[-5:])
Validation score for standard linear regression: [0.7549815717405675, 0.7033608157667165, -5.667886382553809, -0.3100673675265291, 0.24877903484777042]
Validation score for LASSO: [0.203027700962511, 0.33477054239299164, 0.16070213355583274, 0.19505021823469149, 0.2370499617158901]
Observations
According to the plot of validation scores for standard linear regression and lass regularization, it can be seen that lasso regularization tends to have more stable validation score when the number of features is large. Even though it is generally lower than the scores of standard linear regression, it does not have very much fluctuations and will not get arbitrarily negative.
Part 5. Optional: Bikeshare Data Set
Download and save a data frame of data related to the Capital Bikeshare system in Washington DC:
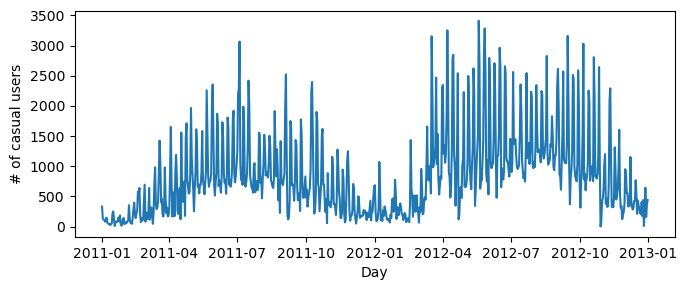
This data set includes information about the season and time of year; the weather; and the count of bicycle users on each day for two years (year 0 is 2011, year 1 is 2012). This level of information gives us considerable ability to model phenomena in the data.
Our aim for this case study is to plot daily usage by casual users (as opposed to registered users). The total number of casual users each day is given by the casual column, Let’s plot this over time:
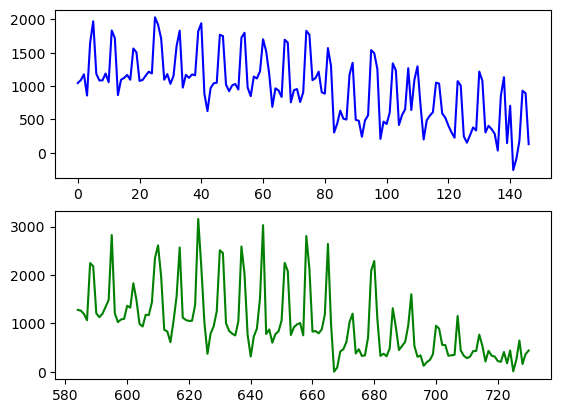
import numpy as npimport matplotlib.pyplot as pltX_test_ = pad(X_test)y_predict= LR.predict(X_test_)ax1 = plt.subplot(211)ax1.plot( y_predict, color ="blue", label ="predict")ax2 = plt.subplot(212)ax2.plot( y_test, color ="green", label ="actual")plt.show()
Compare the entries w of my model to the corresponding entry of X_train.columns in order to see which features my model found to contribute to ridership.
Positive coefficients suggest that the corresponding feature contributes to ridership.
‘yr’,‘temp’, and all “mnth” have positive coefficients, suggesting that they contribute to ridership. Among all, temperature has the highest coefficient, so nice weather has the most significant effect on ridership.