In this blog post, I work through a complete example of the standard machine learning workflow. My goal is to determine the smallest number of measurements necessary to confidently determine the species of a penguin.
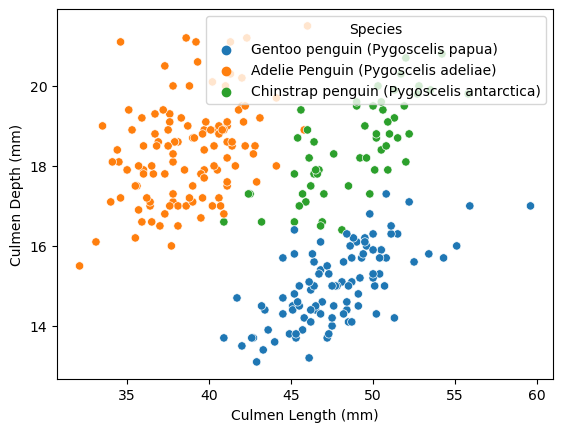
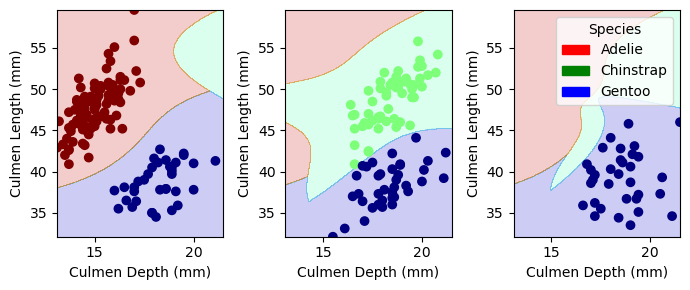
From the plot above, we can easily distinguish three clusters representing the three penguin species.
Therefore, it seems possible to classify them from the combination of culmen depth and culmen length.
(2) Construct displayed table
Then, I construct a displayed table to see how Culmen Length and Body Mass correspond to the islands penguins live and their sex.
import numpy as nptrain.groupby(['Island','Sex'])[['Culmen Length (mm)','Body Mass (g)' ]].aggregate([np.mean, len]).round(2)
Culmen Length (mm)
Body Mass (g)
mean
len
mean
len
Island
Sex
Biscoe
.
44.50
1
4875.00
1
FEMALE
42.94
61
4253.28
61
MALE
47.54
70
5169.29
70
Dream
FEMALE
42.45
49
3435.20
49
MALE
46.49
47
3975.53
47
Torgersen
FEMALE
37.61
18
3380.56
18
MALE
40.66
19
3990.79
19
According to the table above, the penguins living in the Biscoe Island generally have the longest culmen, while the penguins living in the Torgersen Island generally have the shortest culmen.
Also, female penguins tend to have shorter culmen and smaller body mass than male penguins.
Part 2. Model
In this part, I find three good features of the data and train a model on those features, which eventually achieves 100% testing accuracy.
Data Preparation:
I first prepare the data by encoding the categorical features in numerical columns
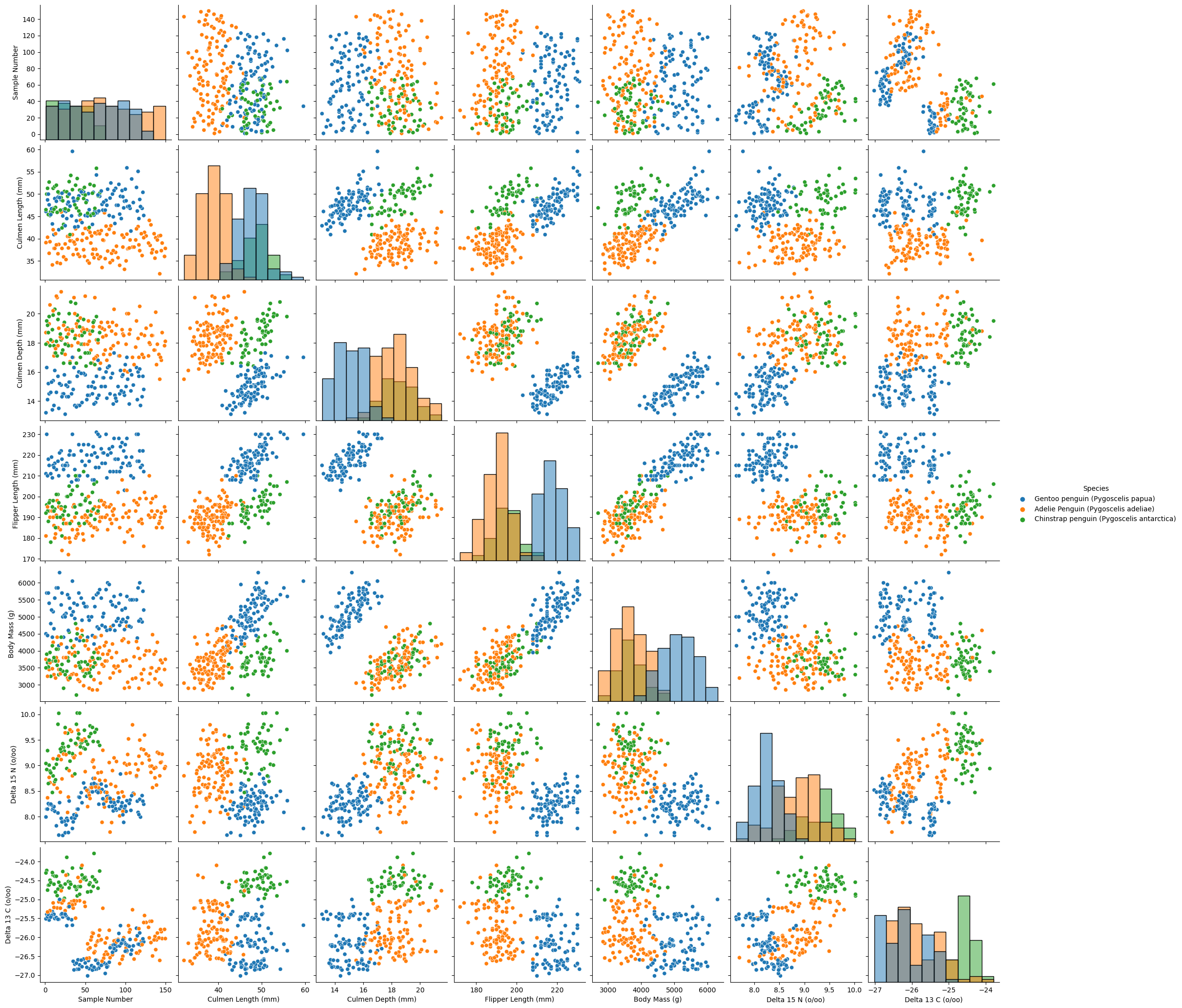
By analyzing the scatter matrix above, I find the combinations of “Culmen Depth”, “Culmen Length”, “Flipper Length” already show three distinctive groups.
I can exclude the features “Body Mass”, “Delta 15N”, “Delta 13C”, as the points are highly overlapping and therefore cannot generate good separable datapoints.
(2) Combination Method for feature selection
Once I sift out some relativaly better fatures, I then want to determine the best two quantitative features together with one qualitative feature.
Specifically, I use the combinations method to try all combinations of (1 qualitative features + 2 selected quantitative features) to see which combination achieves the best training accuracy.
from itertools import combinationsfrom sklearn.svm import SVCfrom sklearn.model_selection import cross_val_scorefrom sklearn.tree import DecisionTreeClassifier, plot_treefrom sklearn.ensemble import RandomForestClassifier# train the three modelssvc = SVC(kernel='rbf', C =800)dtc = DecisionTreeClassifier(max_depth =5)rf = RandomForestClassifier(max_depth=5,n_estimators =11,random_state=0)# select relatively good quantative columns and qualitative columnsall_qual_cols = [ "Sex", "Island"]all_quant_cols = ['Culmen Length (mm)', 'Flipper Length (mm)','Culmen Depth (mm)']for qual in all_qual_cols: qual_cols = [col for col in X_train.columns if qual in col ]for pair in combinations(all_quant_cols, 2): cols = qual_cols +list(pair) print(cols)#get accuracy for all three models svc.fit(X_train[cols], y_train) dtc.fit(X_train[cols], y_train) rf.fit(X_train[cols], y_train)print("svc score:", svc.score(X_train[cols], y_train))print("dtc score:", dtc.score(X_train[cols], y_train))print("rf score:", rf.score(X_train[cols], y_train))
By comparing the three models’ training accuracies for all those combinations, I find that “Island”, “Culmen Length (mm)” and “Culmen Depth (mm)” are the three best features, under which the SVC, DecisionTree, and RandomForest Classifiers all can achieve 100% training accuracy.
Now I will decide which model I will use for the training.
According to the previous analysis and visualization, the data do not seem to be linearly separable. Therefore, the linear model may not be appropriate to model this set of data.
To test the model, I download the test data set and prepare it using the prepare_data function.
To train my model, I will perform the following steps:
Train the model with the train dataset.
Check its training scores and testing scores.
Adjust the hyperparameters using cross validation method.
Test the trained model with the test dataset.
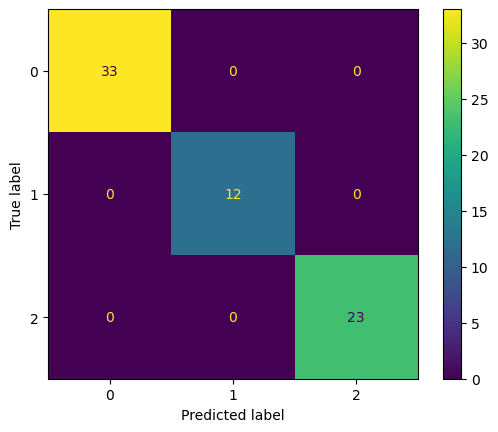
Construct the confusion matrix to validate the model performance.
Support Vector Machine
I choose the SVC model, which takes advantage of kernels to separate and classify data by defining hyperplanes in higher dimensional spaces.
Here I use the “rbf” kernal
Hyperparameters
I take the following two hyperparameters into consideration:
The parameter C indicates how much we care about misclassifications. For large values of C, the algorithm will choose a smaller-margin hyperplane if that hyperplane does a better job of getting all the training points classified correctly. Conversely, a very small value of C will cause the algorithm to look for a larger-margin separating hyperplane, even if that causes more misclassifications.
The parameter gamma determines the reach of each training sample with regards to the boundry. For low values of gamma, every train sample will reach the boundry. For high values of gamma, only values close to the boundry will reach it, and consequently, only these values will influence the boundry.
Data Normalization
The variables in the dataset are measured in different units and therefore have different scales. We would like to have them in a similar scale so that we can compare them in the modelling without giving more importance to the features that have a bigger magnitude. To achieve that, we standardize the numeric columns to have mean zero and variance one.
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
SVC()
Without adjusting any hyperparameters, see the training and testing accuracy of the model
The accuracy is pretty high, but is still less than 1.0.
Now I will adjust some hyperparameters of my SVM model by cross validation to let it achieve the best accuracy. - C - gamma
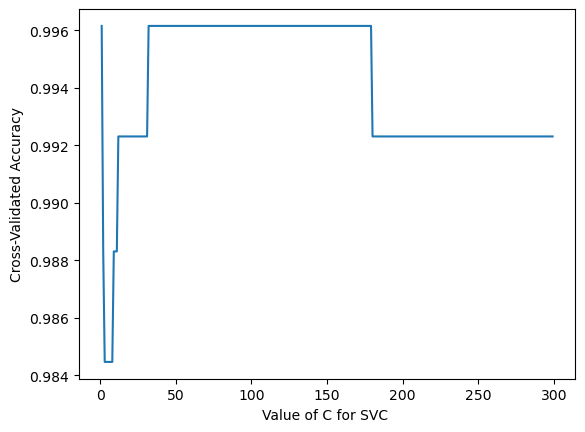
First, I want to find the best value for C:
I create a loop to keep track of the value of C along with the change in cross valization scores
C_range=np.arange(1,300)acc_score=[]for c in C_range: svc = SVC(kernel='rbf', C = c) cv_scores = cross_val_score(svc, X_train[cols], y_train, cv=10, scoring='accuracy') mean_score = cv_scores.mean()#print(f"C = {c}, score = {mean_score.round(5)}") acc_score.append(mean_score)import matplotlib.pyplot as plt%matplotlib inlineC_range=np.arange(1,300)# plot the value of C for SVM (x-axis) versus the cross-validated accuracy (y-axis)plt.plot(C_range,acc_score)plt.xlabel('Value of C for SVC ')plt.ylabel('Cross-Validated Accuracy')
Text(0, 0.5, 'Cross-Validated Accuracy')
Based on the plot, it seems that the cross-validated accuracy achieves the highest score between C = 50-175.
So I will set C = 100.
Now I want to find the best gamma value for my SVM using the same method:
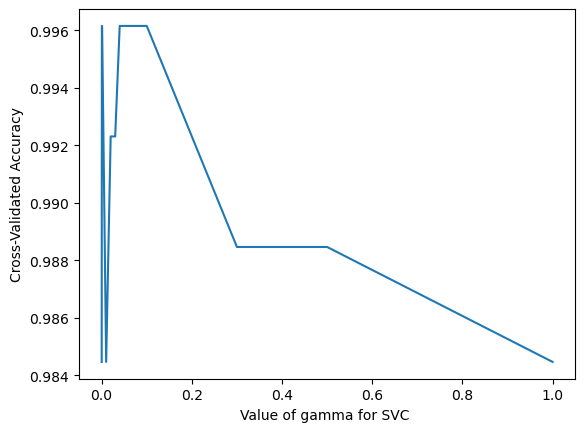
gamma_range=[0.0001, 0.0005, 0.001, 0.01,0.02,0.03,0.04,0.05,0.06,0.1,0.3,0.5,1]acc_score=[]for g in gamma_range: svc = SVC(kernel='rbf', C =100, gamma=g) cv_scores = cross_val_score(svc, X_train[cols], y_train, cv=10, scoring='accuracy') mean_score = cv_scores.mean()print(f"gamma = {g}, score = {mean_score.round(5)}") acc_score.append(mean_score)import matplotlib.pyplot as plt%matplotlib inlinegamma_range=[0.0001, 0.0005, 0.001, 0.01,0.02,0.03,0.04,0.05,0.06,0.1,0.3,0.5,1]# plot the value of C for SVM (x-axis) versus the cross-validated accuracy (y-axis)plt.plot(gamma_range,acc_score)plt.xlabel('Value of gamma for SVC ')plt.ylabel('Cross-Validated Accuracy')
From the graph above which traces the cross-valudation accuracy along with the change in gamma, I find that gamma between 0.04 and 0.1 will achieve the best cross-validation accuracy.
So I will set gamme = 0.04.
Tuning
Now I will add the C and gamma value into my SVM model and see how it performs:
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.